
مدیریت مشکل یکی از جنبه های پیاده سازی ITIL است که باعث نگرانی بسیاری از سازمانها شده است. مشکلی که در اینجا وجود دارد شباهت بین مدیریت رخداد (incident management) با مدیریت مشکل (problem management) است. این دو فرآیند بسیار با یکدیگر هم راستا بوده و تمایز بین فعالیتهای آنها برای تازه کارهای ITIL دشوار است. در چه نقطه ای این دو فرآیند به یکدیگر تبدیل میشوند؟ در برخی سازمانها، این دو فرآیند با یکدیگر مرتبط بوده و با هم ترکیب میشوند. با این حال، تفاوتهای بین این فرآیندها نیز مهم هستند زیرا این دو فرآیند یکسان نبوده و اهداف متفاوتی دارند.
اصطلاح “مشکل (problem)” به علت ناشناخته ای اشاره دارد که منجر به وقوع یک یا چند رخداد میشود. یک تشبیه مفید و کاربردی برای درک ارتباط بین مشکلات و رخدادها، این است که فکر کنید رابطه بین یک بیماری و علائم آن چیست. در این تشبیه، مشکل همان بیماری است و علائم بیماری نیز رخدادها هستند. درست همانطور که یک پزشک از علائم برای تشخیص بیماری استفاده میکند، مدیریت مشکل نیز از رخدادهای بوجود آمده برای تشخیص مشکل استفاده میکند.
هنگامی که رخدادها اتفاق می افتد، نقش مدیریت رخداد، بازگرداندن سرویس در سریعترین زمان ممکن است بدون آنکه نیازی به شناسایی یا برطرف ساختن علت رخداد باشد. اگر رخدادها به ندرت رخ دهند یا تاثیر ناچیزی داشته باشند، در چنین حالتی دلیلی برای تخصیص منابع جهت انجام تجزیه و تحلیل علت ریشه ای رخداد، وجود ندارد. با این حال، اگر یک رخداد مجزا یا دنباله ای از رخدادهای تکراری باعث تاثیر قابل توجهی شوند، مدیریت مشکل به تشخیص علت اصلی رخدادها و در نهایت شناسایی ابزاری برای از بین بردن این علت میپردازد.
اولین فعالیت problem management این است که مشکل را تشخیص داده و راه حل های موجود را شناسایی کند. Problem management از یک پایگاه داده مشکل برای پیگیری مشکلات و مرتبط سازی راه حل های مشخص شده با آنها استفاده میکند. پس از آنکه مشکل و راه حل آن مشخص شد، این مشکل به عنوان یک “خطای شناخته شده” در نظر گرفته میشود. این خطاها در پایگاه داده خطاهای شناخته شده (KEDB) که ممکن است یک پایگاه داده فیزیکی همانند پایگاه داده مشکل باشد، مستند میشوند. KEDB ابزار مهمی برای مدیریت رخدادها در حل رخداهای ناشی از خطاهای شناخته شده است.
پس از شناسایی خطای شناخته شده، مرحله بعدی تعیین نحوه رفع آن است. اینکار معمولا شامل یک تغییر در یک یا چند CI میباشد، بنابراین خروجی فرآیند مدیریت مشکل، یک درخواست تغییر است که پس از آن توسط فرآیند مدیریت تغییر ازریابی شده و یا در فهرست CSI لحاظ میشود.
Problem management به عنوان یک فرآیند واکنشی در نظر گرفته میشود که پس از وقوع رخداد اتفاق می افتد، اما در حقیقت یک فرآیند پیشگیرانه است، زیرا هدف آن این است که اطمینان حاصل کند رخدادها در آینده رخ نخواهند داد یا اگر رخ دهند، تاثیر آنها را به حداقل خواهد رساند.
101Problem Management
Problem management یک گام فراتر از مدیریت رخداد در مرحله عملیات سرویس در چرخه حیات ITIL است. Incident management هرگونه وقفه پیش بینی نشده یا کاهش کیفیت سرویس فناوری اطلاعات را کنترل و مدیریت میکند، درحالیکه problem management علت اصلی رخدادها را کنترل و مدیریت میکند. به بیان ساده تر، incident management سرویسها را بازیابی میکند در حالیکه problem management علت شکست سرویسها را برطرف میکند.
“مشکل” در ITIL به عنوان علت یک یا چند رخداد تعریف میشود. برخی رخدادها مانند یک موس خراب در یک ایستگاه کاری کاربر، نشانگر مشکل نیستند. در خصوص سایر رخدادها همچون قطع شدن مکرر شبکه بدلیل آنکه مرتبا تکرار میشوند باید مشکل را بررسی نمود. در چنین شرایطی problem management بصورت واکنشی عمل میکند. مدیریت مشکل پیشگیرانه شامل رسیدگی به وضعیت سخت افزار، نرم افزار و فرآیندها و همچنین رسیدگی به مسائل قبل از آنکه رخدادهای بیشماری را بوجود آورند. مدیریت رخداد و مدیریت درخواست هیچکدام قادر نیستند همانند مدیریت مشکل، بصورت پیشگیرانه عمل کنند.
هدف مدیریت تغییر
هنگامیکه کاربران بطور مداوم با رخدادهای مشابهی که برطرف نشده اند، مواجه شوند، اعتماد خود را نسبت به قابلیت service desk در حل مشکلات از دست خواهند داد. از این رو، هدف اصلی مدیریت مشکل، شناسایی، عیب یابی، مستندسازی و برطرف ساختن علل اصلی و ریشه رخدادهای تکراری است. اطلاعات مربوط به رخدادها در problem management فیلتر شده و در نتیجه problem management خطاهای شناخته شده و اطلاعات مربوط به راه حل مورد نیاز جهت مقابله با مشکلات در کوتاه مدت را برای service desk فراهم میکند.
مشکلات شامل مسائلی از قبیل خرابی سخت افزار یا ناکارامد بودن query تنظیم شده پایگاه داده است. Problem management تعداد رخدادها را در طولانی مدت کاهش میدهد.کاهش رخداد، بار کاری service desk را کاهش داده و رضایت کاربر نهایی را افزایش میدهد، بعلاوه هزینه های مربوط به کاربران و خرابی سرویس را در طولانی مدت کاهش میدهد. هنگامیکه مشکلات برطرف نشود، problem management با service desk همکاری کرده تا بتواند میزان اثرگذاری رخدادهای مرتبط را کاهش دهد. هدف نهایی problem management همواره باید کاهش تعداد کلی رخدادهای قابل پیشگیری و در نتیجه افزایش کیفیت خدمات ارائه شده باشد.
دامنه مدیریت مشکل
Problem management دامنه بسیار محدودی داشته و شامل فعالیتهای زیر است:
- تشخیص مشکل (Problem detection)
- ثبت مشکل (Problem logging)
- دسته بندی مشکل (Problem categorization)
- اولویت بندی مشکل (Problem prioritization)
- تحلیل و بررسی مشکل (Problem investigation and diagnosis)
- ایجاد رکوردی از خطای شناخته شده (Creating a known error record)
- حل مشکل و بستن آن (Problem resolution and closure)
- بازنگری مشکل اصلی (Major problem review)
نقش اصلی مدیریت مشکل
Problem management وظایف و نقشهای زیادی دارد که مهمترین آن service desk است. با اینکه service desk، با عنوان “help desk” نیز شناخته میشود، اما اصطلاح مورد قبول ITIL نبوده و باید از بکارگیری آن خودداری نمود. این نقش در ITIL به عنوان تنها نقطه تماس برای مشتریان سرویسها جهت گزارش رخدادها و ارسال درخواستهای سرویس عمل میکند. بدون وجود یک نقطه تماس، کاربران ممکن است با کارکنان تماس گرفته و انتظار داشته باشند سرویسها را فوری و بدون هیچ گونه محدودیت اولویت بندی دریافت کنند. متاسفانه، این بدان معناست که رخدادهای فوری نادیده گرفته شده و رخدادهایی که تاثیر چندانی بر کسب و کار نمیگذارند، در ابتدا انجام میشوند. یکی دیگر از سناریوهای معمول این است که رخدادهای مهم اما کم اهمیت برای هفته ها رسیدگی نمیشوند، زیرا کارمندان پشتیبانی فناوری اطلاعات مشغول رسیدگی به مسائل فوری در service desk خود بوده و زمانی برای مسائل کوچکتر صرف نمیکنند. Service desk به سرویس دهندگان امکان میدهد تا بطور پیوسته و فوری به مسائل و مشکلات هر فرد رسیدگی کند. همچنین به انتقال دانش بین دپارتمانها کمک کرده و داده های مربوط به روندهای IT را جمع آوری و امکان مدیریت مشکل را فراهم میکند.
این نقش میتواند به سطوح پشتیبانی مجزا یا به عبارتی چند لایه مجزا تقسیم شود. لایه نخست برای مشکلات پایه ای است. این مشکلات شامل مسائلی با اولویت پایین هستند مانند عیب یابی اولیه کامپیوتر. رخدادهای لایه اول به احتمال زیاد به مدل های رخداد تبدیل میشوند، زیرا به سادگی قابل حل بوده و اغلب رخ میدهند. رخدادهای لایه اول تاثیری بر کسب و کار و سایر کاربران نمیگذارند. تا زمانیکه این رخدادها توسط service desk برطرف میشوند، به راحتی میتوان بر آنها غلبه کرد. برای مثال خطای Outlook مایکروسافت میتواند از طریق جایگزینی با برنامه ایمیل مبتنی بر وب برطرف شود.
سطح پشتیبانی لایه دوم آن دسته از مشکلاتی را که تنها بر کاربر تاثیر داشته اما بر روی کسب و کار اثری ندارد را کنترل و مدیریت میکند. معمولا حل این گونه رخدادها به مهارت یا دسترسی بیشتری نیاز دارد. رخدادهای لایه دوم، دارای اولویت متوسط بوده و به پاسخهای فوری بیشتر و سطح بالایی از دسترسی یا آموزش نسبت به رخدادهای لایه اول نیاز دارند.
رخدادهای لایه سوم، کل سازمان و بسیاری از کاربران را تحت تاثیر قرار میدهند. در برخی موارد، ممکن است یک کاربر VIP به دسته بندی سطح دوم یا سطح سوم رفته تا زمان پاسخگویی به این کاربران سریعتر شود. این رخدادها اغلب وارد فرآیند اصلی پاسخ به رخداد (Major Incident Response) میشوند. بر اساس تعریف ITIL، اینها همان رخدادهایی هستند که منجر به بروز اختلالات عمده در کسب و کار میشوند. این رخدادها همیشه اولویت بالایی دارند. رخدادهایی که به فرآیند اصلی پاسخ به رخداد نیاز دارند، کاندیدهای خوبی برای مشکلات احتمالی هستند، زیرا آنها بر کسب و کار اثر گذاشته و به احتمال زیاد علت اصلی وقوع آنها با رخدادهای معمولی تفاوت دارد.
هنگامیکه اکثر رخدادها در لایه نخست با اولویت پایین قرار داشته و تعداد کمتری از رخدادها در لایه دوم و تنها تعداد بسیار کمی نیز در لایه سوم قرار دارند، بدین معناست که لایه ها و اولویتها را به دقت ارزیابی کرده اید.
Service desk به چندین روش با تیم problem management ارتباط برقرار میکند. اولین تعامل هنگامی است که یک مشکل بالقوه مطرح میشود. این ارتباط زمانی برقرار میشود که یک رخداد برای service desk غیر قابل حل بوده و میبایست ارجاع داده شود و یا هنگامیکه یک رخداد با وجود عیب یابی های انجام شده و حل شدن مجددا تکرار میشود. در نهایت، هنگامیکه تیم problem management یا continual service improvement (بهبود مستمر سرویس) مشکلات را پیش از مواجهه با آنها شناسایی میکنند، در چنین شرایطی ممکن است جهت کسب اطلاعات بیشتر یا آمار رخدادها با service desk تماس برقرار کنند.
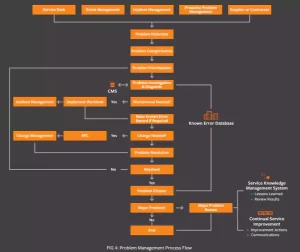
فرآیند مدیریت مشکل (Problem Management Process)
فرآیند problem management در ITIL مراحل زیادی دارد و هر مرحله برای موفقیت فرآیند و کیفیت سرویسهای ارائه شده اهمیت بسیاری دارد.
اولین مرحله تشخیص مشکل است. یک مشکل یا از طریق ارجاع از service desk ایجاد میشود یا از طریق ارزیابی الگوهای رخداد پیش از وقوع رخداد و هشدارهایی که از سمت مدیریت رویداد و فرآیندهای بهبود مستمر سرویس می آید. نشانه های یک مشکل شامل موارد زیر است:
- رخدادهایی که در سراسر سازمان با شرایط یکسان رخ میدهند.
- رخدادهایی که با وجود عیب یابی موفقیت آمیز، تکرار میشوند.
- رخدادهایی که در service desk قابل حل نیستند.
دومین مرحله ثبت مشکل است. در چارچوب ITIL، مشکلات در یک رکورد مشکل (problem record) ثبت میشوند. یک رکورد مشکل، تلفیقی از همه مشکل در یک سازمان است. ثبت این مشکلات در داخل یک رکورد امکانی است که از طریق یک سیستم تیکتینگ برای انواع درخواستهای مشکل فراهم میشود. داده های مربوط به مشکلات همچون زمان و تاریخ وقوع، رخدادهای مرتبط، علائم، مراحل عیب یابی های قبلی و دسته بندی مشکلات همگی به تیم مدیریت مشکل کمک میکند تا ریشه مشکلات را پیدا کنند.
سومین مرحله به دستبه بندی مشکلات اختصاص دارد. دسته بندی مشکلات میبایست با دسته بندی رخدادها مطابقت داشته باشد. این مرحله در چندین روش سودمند است. یک مزیت آن است که به service desk امکان میدهد تا رخدادها را بطور منظم مرتب سازی و مدل سازی کند. مدلسازی امکان تخصیص خودکار اولویتها را فراهم میسازد. سومین و مهمترین مزیت، داشتن قابلیت جمع آوری داده ها و گزارش دهی از داده های service desk است. این داده ها به سازمان امکان میدهد که نه تنها روند مشکلات را پیگیری کرده، بلکه بتواند تاثیر آنها را بر میزان تقاضای سرویس و ظرفیت سرویس دهنده ارزیابی کند.
مرحله چهارم مربوط به اولویت بندی کردن مشکلات میباشد. اولویت یک مشکل بر اساس میزان تاثیر آن بر کاربران و کسب و کار و همچنین فوریت آن تعیین میشود. فوریت بدین معنا است که سازمان چقدر سریع مشکلات را برطرف میکند. تاثیر نیز به معنای اندازه گیری میزان آسیب احتمالی است که این مشکل می تواند در سازمان ایجاد کند. اولویت بندی کردن مشکلات به سازمان امکان میدهد که از منابع تحقیقاتی بطور مؤثر استفاده کند. همچنین به سازمان کمک میکند تا میزان تخطی از توافق نامه سطح سرویس را از طریق تخصیص مجدد منابع به محض شناخت مساله (مشکل)، کاهش دهد.
مرحله پنجم یک فرآیند دو مرحله ای شامل بررسی و تشخیص مشکل است. سرعت بررسی و تشخیص مشکل به اولویت تخصیص داده شده به آن مشکل دارد. مشکلاتی که اولویت بالایی دارند باید همیشه در ابتدا رسیدگی شوند زیرا تاثیر آنها بر سرویسها بیشتر است. دسته بندی صحیح در اینجا کمک میکند، زیرا شناسایی روند ها در زمانی که دسته بندی مشکلات با دسته بندی رخدادها مطابقت دارد، آسان تر است. تشخیص مشکل معمولا شامل تجزیه و تحلیل رخدادهایی است که منجر به گزارش مشکلات و همچنین تستهای بیشتری که احتمالا در سطح service desk امکان پذیر نیست، میشود، مانند تحلیل پیشرفته log.
مرحله ششم به شناسایی راه حل مشکل اختصاص دارد. یک راه حل همیشه باید نشان داده شود، زیرا مشکلات در سطح رخداد حل نمیشوند. راه حل، service desk را قادر میسازد تا سرویسها را هنگامیکه مشکل در حال رفع شدن است، بازیابی کند. حل یک مشکل می تواند از یک ماه تا چند ماه به طول بینجامد، بنابراین وجود یک راه حل برای آن بسیار حیاتی است. یک مشکل تا زمانیکه حل نشود، در وضعیت “باز” باقی میماند، بنابراین یک راه حل باید تنها به عنوان یک معیار موقت در نظر گرفته شود.
مرحله هفتم مربوط به ایجاد رکوردی از خطاهای شناخته شده است. هنگامی که راه حل شناسایی شد، باید به عنوان یک خطای شناخته شده به کارکنان درون سازمان اعلام شود. اینکار روش خوبی برای ثبت خطای شناخته شده در پایگاه دانش رخداد و هم در پایگاه داده خطاهای شناخته شده (KEDB) است. مستندسازی راه حل ها به service desk امکان میدهد تا رخدادها را به سرعت حل کرده و از وقوع مشکلات بیشتر که بر اثر همان رخدادها بوجود می آیند، جلوگیری کند.
مرحله هشتم به حل مشکلات میپردازد. مشکل باید هر زمان که امکان پذیر است، حل شود. راه حل ها، علت اصلی مجموعه ای از رخدادها را برطرف کرده و از وقوع مجدد آن ها جلوگیری میکند. برخی از این راه حل ها ممکن است به هیئت مدیره بخش change management نیاز داشته باشند زیرا ممکن است سطوح سرویس را تحت تاثیر قرار دهند. برای مثال، switchover شدن database ممکن است باعث ایجاد کندی در طول دوره switchover شود. پیش از پیاده سازی راه حل، همه ریسک های آن باید ارزیابی شود. مراحل انجام شده جهت حل مشکل را در داخل پایگاه دانش سازمان، مستند نمایید.
مرحله نهم، بستن مشکل است. این مرحله فقط باید بعد از ایجاد، دسته بندی، اولویت بندی، شناسایی، تشخیص و حل مشکل رخ دهد. با وجود آنکه بسیاری از سازمانها کار را در این مرحله متوقف میکنند، اما برای ITIL پایان کار نیست.
آخرین مرحله، بازنگری مشکل است. بازنگری مشکل اصلی یک فعالیت سازمانی است که از وقوع مشکلات آینده جلوگیری میکند. در طول مرحله بازنگری، تیم problem management مستندات مشکل را ارزیابی کرده و مشخص میکند که چه اتفاقی رخ داده و علت وقوع آن چیست. درسهای آموخته شده، مانند شکاف های موجود در فرآيند، اشتباهی که رخ داده و آنچه که به آن کمک کرده، بايد مورد بحث قرار گيرد. این جایی است که داشتن log کامل از مشکلات کمک خواهد کرد. یک log کامل به مراتب بهتر از تلاش برای گرفتن جزئیات از حافظه، عمل میکند. بازنگری مشکل باید منجر به بهبود فرآیندها، آموزش کارکنان یا مستندات کاملتر شود.
نمودار جریان فرآیند مدیریت مشکل
چگونه مدیریت مشکل را به ITIL متصل می کند
Problem management تنها یک جزء از چرخه حیات مدیریت سرویس ITIL است. مدیریت مشکل در فرآیند اصلی Problem management وجود دارد و به عنوان یک فرآیند با بسیاری از بخشهای ITIL ارتباط دارد. با توجه به ارتباط Problem management با service desk، آن را به طور مستقیم تحت تاثیر قرار داده و بر مدیریت رخداد نیز تاثیر میگذارد. همچنین از آنجا که تاثیر مالی یک مشکل در مراحل اولویت بندی و حل مشکل مشاهده می شود، با مدیریت مالی نیز ارتباط دارد. هنگامیکه مشکلات قبلی و مشکلات احتمالی در طول فرآیند طراحی IT مشاهده میشود، با service design نیز ارتباط برقرار میکند. با مدیریت دانش هنگامیکه خطاهای شناخته شده در آن ذخیره میشوند، ارتباط برقرار میکند. در نهایت نیز با بهبود مستمر سرویس در زمانی که مدیریت مشکل بصورت پیشگیرانه عمل میکند، ارتباط برقرار میکند، زیرا هدف هر دو بهبود کیفیت سرویسهای ارائه شده به مشتریان داخلی و خارجی است.
این فرآیند برای موفقیت ارائه طولانی مدت سرویسها بسیار ضروری است و در نتیجه نباید در هنگام طراحی سرویس های قدرتمند فناوری اطلاعات (چه در داخل و چه در خارج قرار داشته باشد) نادیده گرفته شود.
سوالات متداول
- مدیریت مشکل (Problem Management) چیست؟
مدیریت مشکل یکی از جنبه های پیاده سازی ITIL است که باعث نگرانی بسیاری از سازمانها شده است. مشکلی که در اینجا وجود دارد شباهت بین مدیریت رخداد (incident management) با مدیریت مشکل (problem management) است. این دو فرآیند بسیار با یکدیگر هم راستا بوده و تمایز بین فعالیتهای آنها برای تازه کارهای ITIL دشوار است. - فرآیند مدیریت مشکل چیست؟
اولین مرحله تشخیص مشکل است، دومین مرحله ثبت مشکل است، سومین مرحله به دستبه بندی مشکلات اختصاص دارد، مرحله چهارم مربوط به اولویت بندی کردن مشکلات میباشد، مرحله پنجم یک فرآیند دو مرحله ای شامل بررسی و تشخیص مشکل است، مرحله ششم به شناسایی راه حل مشکل اختصاص دارد. مرحله هفتم مربوط به ایجاد رکوردی از خطاهای شناخته شده است، مرحله هشتم به حل مشکلات میپردازد، مرحله نهم بستن مشکل است و آخرین مرحله، بازنگری مشکل است.