
فهرست مطالب این مقاله:
در این مقاله ابتدا به بررسی رابطه HA و VM Clustering میپردازیم و سپس بررسی میکنیم که چگونه Clustering ماشینهای مجازی میتواند در HA تاثیرگذار باشد.
خرابی سرور میتواند موجب مشکلاتی ویرانگر و هزینههایی گزاف در کسب و کار شود. برای جلوگیری از خطرات ناشی از حوادث غیرقابل پیشبینی میتوان از یک نرم افزار مانیتورینگ شبکه و بازیابی اطلاعات به وسیله کلاسترینگ سرورهای مجازی (VM Clustering) و High Availability (HA) استفاده نمود.

همانگونه که راهبران IT میدانند، کلاسترینگ ماشین مجازی و HA ذاتاً به یکدیگر متصلاند. کلاسترها (گروهایی از دو یا چند سرور که مانند یک سیستم مستقل و تنها عمل میکنند) انعطاف پذیری را با انتقال بار کاری میان سرورهای دیگر در کلاستر ارتقا میدهند. در رخداد خطای یک سرور، ماشینهای مجازی در سروری دیگر از کلاستر مجدد شروع به کار میکنند و در نتیجه بارهای کاری سرور خراب شده به سروری دیگر انتقال پیدا خواهد کرد.
درک ارتباط میان کلاسترینگ ماشین مجازی و HA ممکن است آسان به نظر برسد، اما پیاده سازی آن میتواند به مراتب سخت باشد. ایجاد کلاسترهای HA میتواند وقت گیر باشد، زیرا انتخاب تعداد VMهایی که در کلاستر شما وجود دارد، میتواند بصورت فرضی انجام شده و با چالشهای مختلفی همراه باشد. خوشبختانه ما اینجاییم تا (با مطمئن و ایمن کردن HA با کلاسترینگ ماشین مجازی) به ساده تر کردن این پروسه کمک کنیم.
یافتن توازن مناسب برای High Availability
اگرچه مجازی سازی به گونهای غیر قابل انکار موجب تثبیت سرور و افزایش حجم کاری و قابلیت migration به صورت انعطاف پذیری گشته است، هنوز از تکامل کامل فاصله دارد. به کارگیری حجم کاری بیشتر در سرورهای فیزیکی کمتر میتواند به معنای از دست رفتن حجم وسیعتری از ارتباطات به هنگام وقوع رخداد در خطای سخت افزاری باشد. بهترین راه مبارزه با آسیبپذیریهای ناشی از مجازی سازی، اطمینان حاصل کردن از این است که تمامی المانهای استقرار شما، شامل ماشینهای مجازی و Hypervisorها، انعطاف پذیر و قابل اطمینان باشند.
بهترین روش برای تحقق این امر استفاده از ترکیبی از نرم افزارها و سختافزارهای گوناگون (شامل کلاسترینگ ماشین مجازی، Hot Spare ، Snapshotها و حتی چندین پورت اترنت) به منظور تست میباشد که میتواند باعث توازن صحیح و افزایش دسترس پذیری حجم کاری شود.
چگونه میتوان دسترسپذیری Host و VM را در VSphere پیکربندی کرد؟
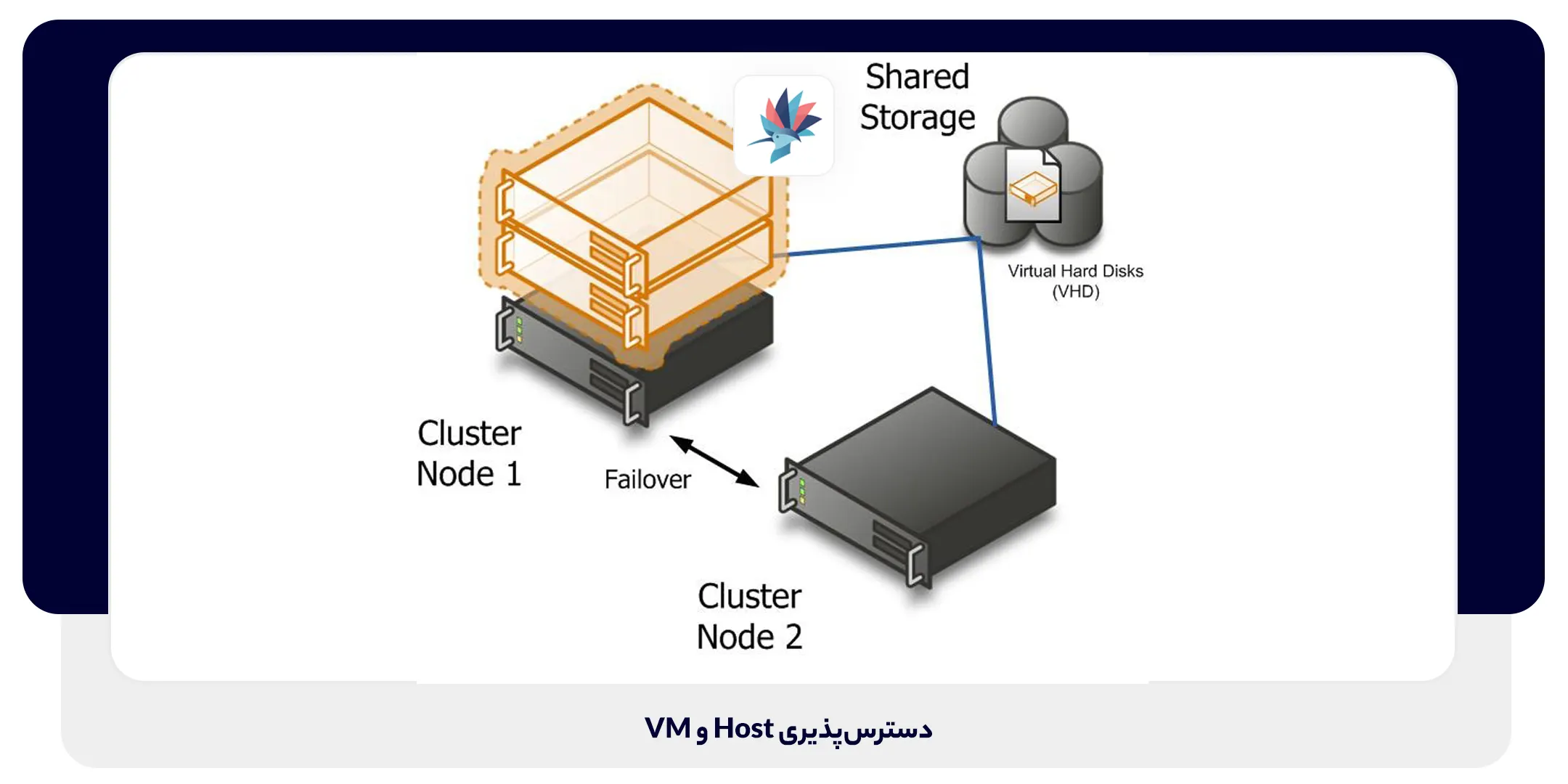
در محیطهای VSphere، Uptime بودن HA بسیار حیاتی است. با استفاده از تنظیمات High Availability در VSphere، کاربران قادر خواهند بود بستر مناسب را برای HA جهت توزیع مجدد حجم کاری پس از Crashهای Host در ESXi و همچنین سیستم عامل VM و خطای برنامه کاربردی فراهم کنند. در واقع این مهم توسط “ضربان قلب یا Heartbeats” (پینگهای ارتباطی ارسال شده از یک VM به HA در VMware انجام میشود.
اگر VM نیازهای ضروری HA را نداشته باشد، HA در VMware آن را Reset خواهد کرد. HA در VMware به یک Host کلاستر شده نیاز دارد که در قالب دو ESXi Host یا بیشتر که از منبع ذخیرهسازی به اشتراک گذاشته شدهای استفاده میکنند، تعریف شده باشد.
آیا PoDها برای مجازی سازی ارزش متحمل شدن سختی کلاسترینگ را دارند؟
زیرساخت PoDها (ماژولی از شبکه، محاسبه، ذخیره سازی و محتوای برنامه کاربردی که با یکدیگر به منظور ارائه خدمات شبکهای کار میکنند. PoD یک الگوی طراحی قابل تکرار است که اجزاء آن قابلیتهای مدولار ، مقیاس پذیری و کنترل پذیری دیتاسنترها را ارتقا میدهد) به صورت همگرا، در بخشهای بزرگ به دلیل پایداری و قابلیت پشتیبانی شهرتی را به عنوان یک ویژگی خوب برای مجازی سازی به همراه داشته است. اگرچه این لزوماً به این معنی نیست که آنها انتخابی مناسب برای هر زیرساخت مجازی هستند، به خصوص وابستگی آنها به HA.
همه PoDها افزونگی را به طور کامل فراهم نخواهند آورد و به همین ترتیب مستلزم تبدیل شدن به یک نقطه شکست (Single Point Of Failure: بخشی از سیستم است که در صورت از کار افتادن آن تراکنشهای کل سیستم متوقف خواهد شد) میباشد. اگر یک PoD به عنوان یک کلاستر در Host به صورت خودمختار به کار گرفته شود، از VMها جهت هدایت Failover به سمت سایر سخت افزارها جلوگیری خواهد کرد. این مورد نباید کاربران را از بکار بردن PoDها جهت اجرای Hostهای مجازی سازی به طور کامل دلسرد کند و میبایست به منظور محافظت هرچه بهتر از مرکز داده (Datacenter) در نظر گرفته شود.
نیازمندیها و چالشهای کلاسترینگ VMware در VSphere
آیا شما در حال جستجو برای پیکربندی دسترس پذیری هرچه بهتر برنامههای کاربردی و افزایش زمان بازیابی در مرکز داده خود هستید؟ کلاسترهای سرور جهت حفظ دسترسپذیری در برابر خطا با ایجاد مجموعهای از قابلیتهای محاسباتی از ریست کردن مکرر VMهای Fail شده به اثبات رسیدهاند. VMware VSphere ویژگیهایی برای کلاسترینگ در دیتاسنترهای بر پایه مایکروسافت فراهم میآورد و ویژگیهای کلاسترینگ را برای Exchange و SQL Server پشتیبانی میکند که ساختن آن یک جایگزین مشخص برای کلاسترینگ در محیط مایکروسافت است.
به خاطر داشته باشید که اگرچه کلاسترینگ ممکن است راه حلی ساده جهت حفظ HA باشد، اما با مجموعهای منحصربفرد از چالشها و پیش نیازها همراه است. کلید موفقیت در کلاسترینگ VM، قابلیت همکاری و ارزیابی معماری کلاستر به صورت مکرر میباشد.
چگونه میتوان از عملکرد صحیح یک سرور HA یا کلاستر مطمئن شد؟
جلوگیری از خطای HA در سرور برای هر سازمان IT حیاتی است، اما تست کلاسترهای HA میتواند به برخی دلایل ریسکپذیر باشد. اگر تیمهای IT تست کلاسترهای HA را بدون هیچ نوع بکاپی انجام دهند، آنگاه خود را در ریسک فروپاشی سیستمهای خود در طول عملیات تست قرار میدهند. با وجو آنکه تیمهای IT اقدام به اجرای تستهایی در این زمینه میکنند، نرم افزارهایی نیز وجود دارند که از سیستمها پشتیبانی میکنند اما بدلیل هزینهبر بودن برای استفاده در کسب و کارهای کوچک چندان مناسب نیستند.
بنابراین سوال این است که آیا تیم IT حتی باید دردسر تست کلاسترهای HA را هم متحمل گردد یا باید باور خود را در اطمینان به سیستم قرار دهد؟ به نظر میرسد متخصصان موافق این هستند که تست کلاسترهای HA یک ضرورت است، زیرا تغییرات سرور و وابستگی در هر زمان میتواند رخ دهد، اما در خصوص اینکه در چه بازه زمانی تستها باید انجام گیرند هنوز اتفاق نظری صورت نگرفته است.