یادگیری ماشین یا Machine Learning که به اختصار با عنوان ML هم شناخته میشه، یکی از زیرمجموعه ها یا کاربردهای هوش مصنوعیه. این تکنولوژی به اپلیکیشن ها و سیستم های نرم افزاری اجازه میده در پیش بینی خروجی ها دقت بیشتری داشته باشن.
ماشین لرنینگ نیاز به برنامه نویسی های خیلی پیچیده برای پیش بینی بهتر رو از بین می بره و این قدرت رو داره تا با توجه به شرایط و داده های در دسترس، تصمیمات هوشمندانه ای بگیره.
الگوریتم های یادگیری ماشین با استفاده از داده های تاریخی به عنوان ورودی، مقادیر خروجی جدیدی رو محاسبه یا پیش بینی می کنن. هدف اصلی اینه که کامپیوترها بتونن به صورت خودکار یاد بگیرن و برای انجام اعمال مشخص نیاز به نظارت یا کمک انسان نداشته باشن.
چرا یادگیری ماشین مهم است؟
ماشین لرنینگ به عنوان یکی از زیرمجموعههای تکنولوژی هوش مصنوعی به یک سیستم کامپیوتری یاد میده چطور سریع تر و باهوش تر باشه. برای تقلید از هوش انسان، کامپیوترها باید از تجربیات گذشته یاد بگیرن و در نتیجه نکات لازم رو با نرخ بیشتر و سریع تری به دست بیارن.
بدین ترتیب میتونیم بگیم یادگیری ماشین مثل یک فرآیند بهینه سازی برای تکنولوژیهای هوش مصنوعیه و مهندس یادگیری ماشین مسئولیت ارائه آموزش بهتر و سریع تر برای راهکارهای هوش مصنوعی رو برعهده داره. این کار با استفاده از توسعه الگوریتمهای بهینه تر و هوشمندتر انجام میشه.
هدف از فرآیند machine learning اینه که راهکارهای هوش مصنوعی سریع تر و هوشمندتر بشن تا در نهایت نتایج حتی بهتری رو در وظایف مشخص شده به دست بیارن. تکنولوژی هوش مصنوعی این توانایی رو داره تا روی جامعه و روشهای مدرن تجارت تاثیر چشمگیری بذاره. این تکنولوژی میتونه وظایف روزمره از برنامه ریزی گرفته تا لجستیک، عملیات و تولید رو متحول کنه.
اگرچه یادگیری ماشین تکنولوژی جدیدی به حساب میاد، اما الگوریتمهای اون سالهاست که وجود دارن. اما با توجه به پیشرفتهای تکنولوژیکی مهمی که اخیرا اتفاق افتاده، فرآیندهای یادگیری ماشین کم کم دارن جایگاه خودشون رو در دنیای تجارت پیدا میکنن. این پیشرفتها شامل موارد زیر میشه:
دسترسی وسیع تر به حجم و تنوع اطلاعات به مراتب بیشتر از قبل، به خصوص به لطف توسعه و گسترش کاربردهای کلان داده یا Big Data.
راهکارهای به مراتب مقرون به صرفه تر برای ذخیره سازی اطلاعات که امکان نگهداری و تولید مجموعه های وسیعی از اطلاعات رو برای سازمان ها میسر کرده.
افزایش قدرت پردازشی که به کامپیوترها و به خصوص راهکارهای AI اجازه میده محاسبات پیچیده رو در زمان کوتاه تری انجام بدن.
این پیشرفتها باعث شدن تا نتایج کسب شده با یادگیری ماشین به طور محسوسی بهبود پیدا کنه. به همین دلیل الان اکثر سازمانها و کسب و کارها در تقریبا هر صنعتی امکان بهره گیری از این تکنولوژی پیشرفته رو دارن.
آشنایی با چند روش محبوب ماشین لرنینگ
الگوریتمهای یادگیری ماشین اغلب در دو دسته تحت نظارت یا بدون نظارت طبقه بندی میشن. در این بخش شما رو با 4 روش محبوب در بین الگوریتمهای هوش مصنوعی آشنا میکنیم.
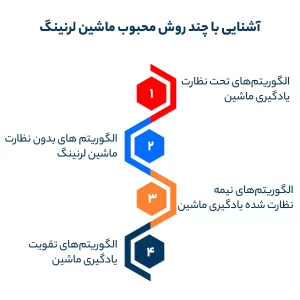
– الگوریتمهای تحت نظارت یادگیری ماشین
این نوع از الگوریتمها با استفاده از به کارگیری آموختههای قبلی بر روی داده جدید و مثالهای نشانه گذاری شده میتونن رویدادهای آینده رو پیش بینی کنن.
این الگوریتمها کارشون رو با آنالیز یک مجموعه داده ی آموزشی شناخته شده و مشخص شروع میکنن. سپس الگوریتم یادگیری یک قابلیت استنباطی رو ایجاد میکنه که میتونه خروجی مقادیر خروجی مجموعه اطلاعاتی جدید رو پیش بینی کنه.
این سیستم بعد از آموزش مناسب میتونه برای هر ورودی جدید اهدافی رو تعیین کنه. الگوریتم یادگیری در این سیستم همچنین میتونه خروجی خودش رو با خروجی صحیح و مورد انتظار مقایسه و برای تغییر مدل، خطاها رو شناسایی کنه.
– الگوریتم های بدون نظارت ماشین لرنینگ
این الگوریتمها در نقطه مقابل قرار دارن و زمانی به کار میرن که اطلاعات مورد استفاده دسته بندی یا نشانه گذاری نشده باشه. الگوریتم یادگیری بدون نظارت کارش رو با مطالعه نحوه عملکرد سیستمها شروع میکنه تا در نهایت بتونه یک ساختار یا الگوی مخفی رو در یک مجموعه نشانه گذاری نشده از اطلاعات، شناسایی کنه.
این سیستم نمیتونه خروجی صحیح رو تشخیص بده اما میتونه اطلاعات رو بررسی کنه و با توجه به مجموعه های اطلاعاتی در دسترس، استنباطهای خودش رو برای وجود ساختارهای مخفی در اطلاعات نشانه گذاری نشده ارائه بده.
– الگوریتمهای نیمه نظارت شده یادگیری ماشین
از اونجایی که این الگوریتم قابلیت استفاده از دادههای نشانه گذاری شده یا نشده رو داره، جایی در بین یادگیری تحت نظارت و بدون نظارت قرار میگیره. معمولا برای آموزش این الگوریتم ها از مقدار کمی دادههای نشانه گذاری شده و مقدار زیادی داده نشانه گذاری نشده استفاده میکنن.
سیستمهایی که از این روش استفاده می کنن، این توانایی رو دارن تا دقت یادگیری رو تا حد زیادی افزایش بدن. معمولا یادگیری نیمه نظارت شده وقتی انتخاب میشه که برای یادگیری از داده نشانه گذاری شده یا آموزش اون به منابع تخصصی و مرتبط نیاز باشه. اما استفاده از داده نشانه گذاری نشده عموما به منابع اضافی نیازی نداره.
– الگوریتمهای تقویت یادگیری ماشین
این الگوریتمها در واقع یک روش یادگیری هستن که با تولید کُنِشها و شناسایی خطاها یا پاداشها، با محیط اطراف خودشون تعامل برقرار میکنن. جستجوی آزمون و خطا و پاداش تاخیری دو مورد از خصوصیاتی هستن که در اکثر الگوریتمهای تقویت ماشین لرنینگ دیده میشه.
این روش به ماشینها و عوامل نرم افزاری اجازه میده تا به صورت خودکار بهترین رفتار رو یک حوزه خاص تشخیص بدن و عملکرد اون حوزه رو به حداکثر برسونن. برای یادگیری اینکه کدوم کنش بهترین کنش ممکن هستش، یک بازخورد ساده در قالب پاداش مورد نیازه. این بازخورد رو با عنوان سیگنال تقویت هم میشناسن.
یادگیری ماشین در چه جاهایی استفاده میشود؟
امروزه ماشین لرنینگ کاربردهای وسیعی داره و شاید یکی از رایج ترین و شناخته شده ترین کاربردهای اون موتورهای نرم افزاری پیشنهاد دهنده محتوا باشه. این موتور در بسیاری از شبکههای اجتماعی مطرح جهان مثل اینستاگرام و فیسبوک مورد استفاده قرار میگیره.
مدیریت ارتباط با مشتری
نرم افزارهای CRM میتونن با استفاده از مدلهای یادگیری ماشین ایمیلهای دریافتی رو آنالیز کنن و مهمترین ایمیل هایی که باید با اولویت بالا پاسخ داده بشن رو به اعضای تیم فروش معرفی کنن. سیستمهای پیشرفته تر حتی میتونن پاسخهای موثر و مناسب رو هم به کارشناسان فروش پیشنهاد بدن.
ایجاد سیستمهای ماشین لرنینگ خوب به چه مواردی نیاز دارد؟
ایجاد یک مدل یادگیری ماشین متغیر، قابل اطمینان و چابک که بتونه عملیاتها رو تسهیل و برنامه ریزیهای کسب و کار رو تقویت کنه نیازمند صبر، آمادگی و پشتکار هستش. در این بخش به 7 گام مهم برای ایجاد یک مدل یادگیری ماشین اشاره میکنیم.
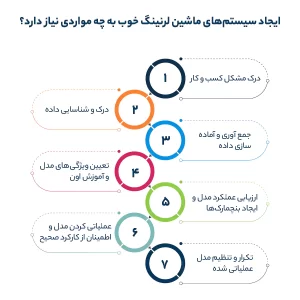
گام اول: درک مشکل کسب و کار
گام اول در هر پروژه یادگیری ماشین، درک مشکلات و نیازمندیهای یک کسب و کار هستش. شما باید بدونین قراره چه مشکلی رو حل کنین تا در نهایت به یک راهکار مناسب برسین. طرح این سوالات و پاسخ دهی یا حتی تلاش برای پاسخ دهی به اونها باعث میشه تا شانس موفقیت پروژه ماشین لرنینگ شما بالاتر بره.
همچنین بهتره اهداف مشخص و قابل اندازه گیری رو تعیین کنین تا نرخ بازگشت سرمایه یا ROI ناشی از انجام این پروژه رو اندازه گیری کنین. اهداف شما باید باید اهداف کسب و کار کاملا هم سو باشه.
گام دوم: درک و شناسایی داده
احتمالا با خودتون فکر میکنین حالا که نسبت به نیازمندیهای کسب و کار و مشکلات اون درک مناسبی دارین و تاییدیههای لازم برای انجام پروژه رو هم دریافت کردین، میتونین ساخت مدل یادگیری ماشین رو شروع کنین. اما جواب منفیه! شما هنوز داده ی لازم برای ساخت یک مدل ماشین لرنینگ رو در اختیار ندارین.
یک مدل یادگیری ماشین با استفاده از یادگیری و عمومی سازی داده ی آموزشی ساخته میشه و سپس دانشی که به دست آورده رو برای مجموعه جدیدی از داده به کار می بره. قبل از شروع باید داده ی مورد نیاز رو شناسایی کنین و مطمئن بشین داده ی انتخابی برای آموزش الگوریتم، مناسب باشه.
منابع جمع آوری داده، حجم داده، کمیت و کیفیت داده ی آموزشی فعلی و روش مناسب برای نشانه گذاری از موارد مهمی هستن که باید هنگام مشخص کردن داده ی آموزشی الگوریتم، به اونها توجه کنین.
گام سوم: جمع آوری و آماده سازی داده
وقتی داده مورد نیازتون رو شناسایی کردین باید به اون داده طوری فرم بدین تا بتونه به مدل ساخته شده آموزش بده. در این مرحله تمرکز بر روی فعالیتهای ضروری داده محور قرار داره تا بتونین مجموعه داده مورد نیاز برای مدلسازی عملیاتها رو ایجاد کنین.
وظایف آماده سازی داده شامل جمع آوری داده، تمیز کردن داده، تجمیع داده، نشانه گذاری، نرمال سازی و موارد دیگه میشه. تمیز کردن و آماده سازی داده فرآیند وقت گیری هستش. بر اساس نظرسنجی انجام شده، توسعه دهندگان ماشین لرنینگ و دانشمندان داده اعلام کردن جمع آوری و آماده سازی داده میتونه 80 درصد از زمان کل اجرای یک پروژه یادگیری ماشین رو به خودش اختصاص بده.
گام چهارم: تعیین ویژگیهای مدل و آموزش اون
بعد از اینکه داده فرم مناسبی به خودش گرفت و مشکلی که باید در کسب و کارتون حل بشه رو به خوبی شناسایی کردین، حالا وقتشه که فرآیند آموزش دادن به مدل رو شروع کنین. برای این کار باید از داده با کیفیتی که قبلا آماده کردین استفاده کنین و با کمک چند تکنیک و الگوریتم مخصوص، به مدل ایجاد شده آموزش بدین.
این مرحله به انتخاب تکنیک و کاربرد مدل، آموزش مدل، تنظیم فراپارامتر مدل، اعتبارسجی مدل، توسعه و آزمایش مدل، انتخاب الگوریتم و بهینه سازی مدل نیاز داره.
گام پنجم: ارزیابی عملکرد مدل و ایجاد بنچمارکها
از منظر هوش مصنوعی، این مرحله ارزیابی شاخص مدل، محاسبات ماتریس سردرگمی، شاخصهای کلیدی عملکرد یا KPI، معیارهای عملکرد مدل، اندازه گیری کیفیت مدل و تایید نهایی اینکه آیا مدل میتونه اهداف تجاری تعیین شده رو برآورده کنه یا نه رو شامل میشه. در طول فرآیند ارزیابی مدل باید موارد زیر رو انجام بدین:
- مدلها رو با استفاده از مجموعه داده های اعتبارسنجی، ارزیابی کنین.
- مقادیر ماتریس سردرگمی رو برای مشکلات طبقه بندی شده تعیین کنین.
- در صورت استفاده از رویکرد K-Fold، روش هایی رو برای اعتبارسنجی متقاطع این رویکرد تعیین کنین.
- برای عملکرد بهینه، فراپارامترها رو تنظیم کنین.
- مدل یادگیری ماشین رو با مدل پایه یا ابتکاری مقایسه کنین.
ارزیابی مدل میتونه به عنوان تضمین کیفیت یادگیری ماشین هم در نظر گرفته بشه. با ارزیابی کافی عملکرد مدل در زمینه شاخص ها و نیازمندیهای مشخص شده، میتونین تعیین کنین که مدل در شرایط واقعی قراره چه عملکردی رو نشون بده.
گام ششم: عملیاتی کردن مدل و اطمینان از کارکرد صحیح
وقتی به اون سطح از اطمینان رسیدین که مدل یادگیری ماشین شما میتونه در شرایط واقعی هم عملکرد خوبی داشته باشه، وقتش رسیده تا اون رو عملیاتی کنین. این مرحله با عنوان «عملیاتی سازی مدل» هم شناخته میشه. بدین منظور موارد زیر رو در نظر بگیرین:
- مدل رو با ابزاری برای اندازه گیری و نظارت مستمر عملکرد آن به کار ببرین.
- یک خط مبنا یا معیاری رو ایجاد کنین تا با استفاده از اون بتونین تکرارهای آینده مدل رو اندازه گیری کنین.
برای بهبود عملکرد کلی، جنبه های مختلف مدل رو به صورت مداوم تکرار کنین.
عملیاتی سازی مدل میتونه شامل سناریوهای به کارگیری مختلفی در فضای ابری، در محل شرکت و فضاهای بسته یا گروه های محدود و تحت کنترل باشه.
گام هفتم: تکرار و تنظیم مدل عملیاتی شده
اگرچه مدل عملیاتی شده و شما به طور مستمر در حال رصد کردن اون هستین، اما هنوز کار به انتها نرسیده. اغلب اوقات شروع با مقیاس کوچک، بزرگ فکر کردن و تکرارهای مختلف، به عنوان فرمول موفقیت برای پیاده سازی تکنولوژی ها در نظر گرفته میشه.
همیشه فرآیند رو تکرار و در هر تکرار جدید بهبودهایی رو اعمال کنین. نیازمندی های کسب و کار و توانمندی های تکنولوژی تغییر میکنه. علاوه بر این، داده ها در دنیای واقعی به طور غیرمنتظره ای تغییر می کنن. همه ی اینها نیازمندیهای جدیدی رو برای به کارگیری مدل در سیستم ها ایجاد میکنن.
میکرولرنینگ چه محدودیتهایی دارد؟
مانند هر رویکرد دیگری، میکرولرنینگ هم معایب خاص خودش رو داره که قبل از به کارگیری اون بهتره در نظر بگیرین. در ادامه میتونین با محدودیتهای میکرولرنینگ آشنا بشین.
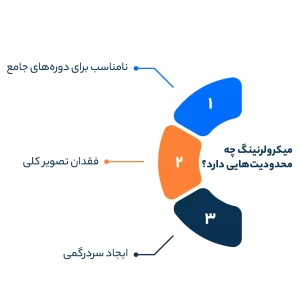
– نامناسب برای دورههای جامع
اگر فکر میکنین میتونین با میکرولرنینگ فیزیک کوانتومی رو آموزش بدین بهتره از همین الان منصرف بشین! این رویکرد آموزشی بیشتر با موضوعات سبک و متمرکز همخوانی داره. موضوعات متناسب با شرایط زمانی، موضوعات ساده و نکات مربوط به وظایف مشخص، از بهترین حوزه هایی هستن که میتونین از رویکرد میکرولرنینگ در اونها استفاده کنین.
– فقدان تصویر کلی
در واقع میکرولرنینگ مثل نگاه کردن از چشمی میکروسکوپه، طوری که شما میتونین بافتها و سلولها رو ببینین اما نمیتونین ببینین این سلولها به چه موجودی تعلق داره. به طور مشابه، فرد یادگیرنده در رویکرد میکرولرنینگ نمیتونه یک تصویر کلی از مسیر آموزشی رو تجسم کنه.
– ایجاد سردرگمی
وقتی مخاطبین با مشکل فقدان تصویر کلی دست و پنجه نرم می کنن، احتمالا نمیتونن نقاط مختلف در مسیر آموزشی طراحی شده رو به همدیگه متصل کنه. به همین دلیل امکان سردرگمی و بی انگیزه شدن افراد وجود دارد.
البته برای رفع این مشکل میتونین موضوعات و اهداف آموزشی رو دقیقا مشخص کنین و تاپیک های مرتبط رو به همدیگه متصل کنین تا مخاطب بدونه در یک مسیر مشخص حرکت میکنه.
آشنایی با بهروشهای میکرولرنینگ
برای بهره گیری از مزایای متعدد رویکرد یادگیری خرد باید با کاربردها و بهروش های استفاده از این رویکرد آشنایی داشته باشین. با استفاده از 7 بهروش زیر میتونین نتایج خیلی خوبی رو از به کارگیری میکرولرنینگ شاهد باشین.
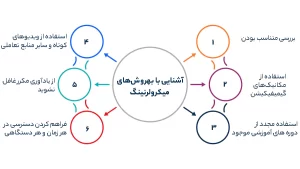
+ بررسی متناسب بودن
میکرولرنینگ بدون شک یک ابزار عالیه اما لزوما برای آموزش تمام موضوعات مناسب نیست. بعضی از وظایف پیچیدگی زیادی دارن و به همین دلیل نمیشه با استفاده از محتواهای کوتاه و کمتر از 10 دقیقه ای آموزش داده بشه.
علاوه بر این، آموزش بعضی از وظایف و موضوعات خاص در قالب دوره های آنلاین، کتاب یا اسلایدشو تقریبا غیرممکنه. این وظایف نیازمند مربیان خبره و جلسات آموزشی حضوری هستش که از طریق رویکرد میکرولرنینگ قابل دستیابی نیست. البته حتی در این شرایط هم میشه به میکرولرنینگ به عنوان یک مکمل آموزشی نگاه کرد.
+ استفاده مجدد از دوره های آموزشی موجود
اگر در حال حاضر دوره ها و محتواهای آموزشی در دسترستون قرار داره، خیلی راحت تر میتونین اطلاعات اونها رو در قالب رویکرد میکرولرنینگ ارائه بدین. برای این کار کافیه بعضی از بخش های دوره های آموزشی موجود به قسمت های کوچکتر تقسیم بشه یا در صورت نیاز محتواهای دوره رو برای تناسب بیشتر با ساختار میکرولرنینگ، تغییر بدین.
+ استفاده از مکانیکهای گیمیفیکیشن
با استفاده از مکانیکها و تکنیک های گیمیفیکیشن میتونین دوره های آموزشی میکرولرنینگ خودتون رو به یک بازی تبدیل کنین. در این شیوه کارمندانتون میتونن حس پاداش و رضایت مندی رو پس از رسیدن به اهداف تعیین شده به دست بیارن.
مثلا بعد از تمام کردن مجموعهای از دوره های آموزشی میکرولرنینگ، اونها میتونن یک نشان افتخار دیجیتالی دریافت کنن. یا میتونین امتیازات کارمندانتون رو نشون بدین تا برای به دست آوردن امتیازات بیشتر، با همدیگه رقابت داشته باشن.
+ استفاده از ویدیوهای کوتاه و سایر منابع تعاملی
همونطور که گفتیم یکی از مزیتهای عالی میکرولرنینگ، افزایش تعامل و درگیری کارمندان در بحث آموزش هستش. اگر بتونین از المان های جذابی مثل ویدیو یا کوییزهای کوتاه استفاده کنین، کارایی برنامه آموزشیتون افزایش پیدا می کنه.
نکته جالب در خصوص ویدیو اینه که همزمان دو حس بینایی و شنوایی ما رو درگیر می کنه و در نتیجه میزان توجه و درگیر شدن مخاطب به طور محسوسی افزایش پیدا می کنه. ویدیوها باید کوتاه باشن و در واقع هر چقدر کوتاه تر باشن، میزان درگیری و به یاد سپردن اطلاعات ارائه شده بیشتر میشه.
+ از یادآوری مکرر غافل نشوید
نتایج تحقیقات ابینگهاوس رو یادتون هست؟ هر چقدر یک محتوا یا اطلاعات در طول زمان بیشتر تکرار بشه، نرخ ماندگاری اون در حافظه هم بالاتر میره. بهتره در پایان هر ماژول آموزشی میکرولرنینگ یا حتی هر موضوع، ابزارهایی رو در اختیار کارمندان قرار بدین تا بتونن چیزهایی که تا الان یاد گرفتن رو مرور کنن.
مثلا میتونین در پایان هر بخش آموزشی از یک کوییز یا اسلاید استفاده کنین تا نکات آموزش داده شده تا اون مرحله رو به افراد یادآوری کنه.
+ فراهم کردن دسترسی در هر زمان و هر دستگاهی
یکی از دلایل جذابیت میکرولرنینگ اینه که کارمندها مجبور نیستن برای یادگیری در محیط شرکت حضور داشته باشن. به همین دلیل، شما باید محتوای آموزشی رو طوری طراحی کنین که کارمندهاتون بتونن در هر زمان و از طریق دستگاه های مختلف مثل گوشی هوشمند یا تبلت به اونها دسترسی داشته باشن.
- انتخاب الگوریتم مناسب با توجه به هدف یادگیری و داده های مورد نیاز
- پیکربندی و تنظیم فراپارامترها برای عملکرد بهینه و تعیین شیوه قابل تکرار برای دستیابی به بهترین فراپارامترها
- شناسایی ویژگی هایی که بهترین نتایج رو ارائه میدن.
- تعیین کنید آیا قابلیت توضیح یا تفسیرپذیری مدل نیاز دارین یا نه.
- برای بهبود عملکرد، مدل های جامع رو توسعه بدین.
- نسخه های مختلف مدل رو برای ارزیابی عملکرد تست کنین.
- الزامات عملکرد و استقرار مدل رو شناسایی کنین.
ماشین لرنینگ چطور کار میکند؟
اگرچه الگوریتمهای یادگیری ماشین به طور کلی به دو دسته تحت نظارت و بدون نظارت تقسیم میشن اما همون طوری که بالاتر هم اشاره شد، میتونیم این الگوریتم ها رو به چهار دسته تحت نظارت، بدون نظارت، نیمه نظارتی و تقویت کننده تقسیم کنیم. در ادامه با نحوه کار هر کدوم از این چهار دسته آشنا میشیم.
– الگوریتم تحت نظارت
یادگیری ماشین تحت نظارت به دانشمند داده ای نیاز داره تا الگوریتم رو با استفاده از دادههای ورودی نشانه گذاری شده و خروجیهای مورد انتظار، آموزش بده. الگوریتمهای یادگیری تحت نظارت برای انجام وظایف زیر مناسب هستن:
- طبقه بندی باینری: تقسیم بندی داده به دو دسته.
- طبقه بندی چندکلاسه: انتخاب از بین بیش از دو جواب.
- مدلسازی رگرسیونی: پیش بینی مقادیر پیوسته.
- جامع سازی: ترکیب پیش بینی های حاصل از چندین مدل یادگیری ماشین برای تولید یک پیش بینی دقیق تر.
– الگوریتم بدون نظارت
الگوریتم های بدون نظارت یادگیری ماشین به داده نشانه گذاری شده نیازی ندارن. اونها با بررسی داده های نشانه گذاری نشده به دنبال الگوهایی هستن تا بتونن دیتا پوینت ها رو در زیرمجموعه های کوچک تری گروه بندی کنن. این الگوریتم ها برای وظایف زیر مناسب هستن:
- خوشه بندی: تقسیم مجموعه داده به گروه های کوچک تر بر اساس الگوهای مشابه.
- تشخیص ناهنجاری: شناسایی دیتا پوینت های غیرمعمول در یک مجموعه داده.
- کاوش شباهت ها: شناسایی مجموعه ای از آیتم ها در یک مجموعه داده که به صورت مکرر با همدیگه ظاهر میشن.
- کاهش ابعاد: کاهش مقدار متغیرها در یک مجموعه داده.
– الگوریتم نیمه نظارتی
یادگیری نیمه نظارتی به این صورت کار میکنه که دانشمندان داده مقادیر کوچکی از داده های نشانه گذاری شده آموزشی رو در اختیار الگوریتم قرار میدن. الگوریتم با استفاده از این مجموعه داده نکات لازم رو یاد می گیره و میتونه اونها رو برای مجموعه داده نشانه گذاری نشده جدید به کار ببره.
عملکرد الگوریتمها عموما وقتی با مجموعه دادههای نشانه گذاری شده آموزش داده میشن افزایش پیدا میکنه. اما آماده سازی داده نشانه گذاری شده میتونه زمان بر و پر هزینه باشه. یادگیری نیمه نظارتی در واقع تلاش می کنه بخشی از مزایای دو شیوه نظارتی و غیرنظارتی رو به صورت همزمان ارائه بده. این نوع الگوریتم ها برای وظایف زیر مناسب هستن:
- ترجمه ماشینی: الگوریتم های آموزشی برای ترجمه یک زبان بر اساس داده هایی کمتر از یک دیکشنری کامل.
- تشخیص کلاهبرداری: شناسایی موارد کلاهبرداری فقط با چند نمونه مثبت.
- نشانه گذاری داده: الگوریتم ها با استفاده از مجموعه داده های کوچک آموزش می بینن تا به صورت خودکار مجموعه داده های بزرگ تر رو نشانه گذاری کنن.
– الگوریتم تقویت
تقویت یادگیری با استفاده از یک الگوریتم برنامه نویسی شده با هدفی مشخص و مجموعه ای از قوانین از پیش تعریف شده برای دستیابی به اون هدف کار میکنه. دانشمندان داده همچنین الگوریتم رو طوری برنامه نویسی میکنن تا به دنبال پاداش های مثبت باشه. وقتی الگوریتم یک اقدام مثبت در راستای رسیدن به هدف انجام بده پاداش دریافت میکنه.
همچنین الگوریتم باید تلاش کنه تا از مجازات های تعیین شده جلوگیری کنه. این مجازاتها وقتی که الگوریتم با اقدامی از مسیر رسیدن به هدف دورتر میشه اتفاق میفته. این نوع از الگوریتم ها برای حوزههای زیر انتخاب خوبی هستن:
- رباتیک: ربات ها با استفاده از این تکنیک یاد می گیرن چطور بعضی از وظایف رو در دنیای واقعی انجام بدن.
- بازی های ویدیویی: یادگیری تقویتی به بعضی از بات ها اجازه میده تا نحوه بازی کردن رو یاد بگیرن.
- مدیریت منابع: با دادن منابع محدود و مشخص کردن هدف، یادگیری تقویتی میتونه به شرکت ها کمک کنه تا اون منابع رو به بهترین شکل تخصیص بدن.
فرآیندهای یادگیری ماشین
یادگیری ماشین مراحلی رو شامل میشه که ساختار یک پروژه ML رو تشکیل میده و به طور موثر منابع شرکت رو تقسیم میکنه. پیروی از این مراحل یا فرآیندها به شرکت ها کمک میکنه تا محصولات هوش مصنوعی پایدار، مقرون به صرفه و با کیفیتی رو ایجاد کنن.
در این بخش ما با استفاده از فرآیند استاندارد بین صنعتی برای توسعه برنامه های یادگیری ماشین با متدولوژی تضمین کیفیت که بیشتر با فرم اختصاری CRISP-ML(Q) شناخته میشه، هر کدوم از این فرآیندها و مراحل در چرخه عمر یک پروژه یادگیری ماشین رو توضیح میدیم.
هر مرحله در چرخه عمر یادگیری ماشین برای بهبود و نگهداری دائمی با پیروی دقیق از الزامات و محدودیت ها از یک چارچوب تضمین کیفیت پیروی میکنه.
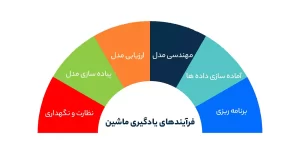
– برنامه ریزی
فرآیند برنامه ریزی شامل ارزیابی دامنه، معیار موفقیت و امکان سنجی برنامه یادگیری ماشین هستش. شما باید کسب و کار و نحوه استفاده از یادگیری ماشین رو برای بهبود فرآیند فعلی درک کنین. مثلا، آیا ما به یادگیری ماشین نیاز داریم؟ آیا میتونیم با برنامه نویسی ساده به نتایج مشابه دست پیدا کنیم؟
شما همچنین باید تجزیه و تحلیل هزینه-فایده و نحوه ارسال راه حل در چندین مرحله رو درک کنین. علاوه بر این، باید معیارهای موفقیت واضح و قابل اندازه گیری رو برای کسب و کار، مدل های یادگیری ماشین (دقت، امتیاز AUC، F1) و اقتصادی (شاخص های کلیدی عملکرد) تعریف کنین.
در نهایت باید یک گزارش امکان سنجی رو ایجاد کنین. این گزارش اطلاعات زیر رو شامل میشه:
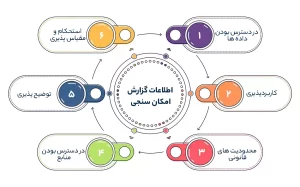
1. در دسترس بودن داده ها
آیا داده های کافی برای آموزش مدل در دسترس قرار داره؟ آیا میتونیم یک منبع دائمی از داده های جدید و به روز رو داشته باشیم؟ آیا میتونیم برای کاهش هزینه از داده های مصنوعی استفاده کنیم؟
2. کاربردپذیری
آیا این راه حل مشکل رو برطرف میکنه یا روند فعلی رو بهبود میده؟ آیا میتونیم از یادگیری ماشینی برای حل این مشکل استفاده کنیم؟
3. محدودیت های قانونی
آیا برای اجرای این راه حل مجوزهای لازم رو از دولت یا سازمان های محلی دریافت کردیم؟ آیا ما از روشی اخلاقی برای جمع آوری داده ها پیروی میکنیم؟ تاثیر این اپلیکیشن روی جامعه چی هستش؟
4. استحکام و مقیاس پذیری
آیا این برنامه به اندازه کافی قوی هستش؟ آیا مقیاس پذیر هستش؟
5. توضیح پذیری
آیا میتونیم توضیح بدیم که چطور مدل یادگیری ماشین به نتایج دست پیدا میکنه؟ آیا میتونیم عملکرد درونی شبکه های عصبی عمیق رو توضیح بدیم؟
6. در دسترس بودن منابع
آیا محاسبات، ذخیره سازی، شبکه و منابع انسانی کافی رو در اختیار داریم؟ آیا به متخصصان واجد شرایط دسترسی داریم.
– آماده سازی داده ها
فرآیند آماده سازی داده ها خودش به چهار بخش تقسیم میشه: جمع آوری و برچسب گذاری داده ها، پاکسازی، مدیریت و پردازش. در ادامه این بخش ها رو توضیح میدیم.

1. جمع آوری و برچسب گذاری داده ها
اول باید تصمیم بگیرین که قراره چطور داده ها رو از داده های داخلی، منابع رایگان، خرید از فروشندگان یا تولید داده های مصنوعی تهیه کنین. هر روش مزایا و معیابی داره و در بعضی موارد، داده ها از هر چهار متدولوژی تهیه میشن.
بعد از جمع آوری، باید داده ها رو برچسب گذاری کنین. خرید داده های تمیز و برچسب گذاری شده برای همه شرکت ها امکان پذیر نیست و همچنین ممکنه لازم باشه در طول فرآیند توسعه در نحوه انتخاب داده ها تغییراتی رو اعمال کنین. به همین دلیل نمیتونین داده ها رو به صورت عمده بخرین چون داده ها در نهایت ممکنه برای راه حل نهایی شما بی فایده باشن.
جمع آوری داده ها و برچسب گذاری به بخش زیادی از منابع شرکت شامل پول، زمان، متخصصان، کارشناسان موضوع و توافق های قانونی نیاز داره.
2. پاکسازی داده ها
در مرحله بعدی، داده ها رو با وارد کردن مقادیر از دست رفته، تجزیه و تحلیل داده هایی با برچسب اشتباه، حذف داده های نامرتبط و کاهش داده های اضافی، پاکسازی یا تصفیه میکنیم. شما برای خودکار کردن این فرآیند و تایید کیفیت داده ها به یک پایپ لاین داده نیاز دارین.
3. پردازش داده ها
مرحله پردازش داده ها شامل انتخاب ویژگی، برخورد با کلاس های نامتعادل، مهندسی ویژگی، تجمع داده ها، نرمال سازی و مقیاس بندی داده ها میشه. برای ثبات بیشتر، باید کلان داده ها، مدل سازی داده ها، پایپ لاین تبدیل و انبار ویژگی ها رو ذخیره و نسخه سازی کنین.
4. مدیریت اطلاعات
در نهایت، راه حل های ذخیره سازی داده، نسخه سازی داده ها برای ثابت بیشتر، ذخیره کلان داده ها و ایجاد پایپ لاین ETL رو در نظر میگیرین و برای هر کدوم یک روش رو در پیش میگیرین. در این مرحله، وجود یک جریان ثابت از داده ها رو برای آموزش مدل تضمین میکنین.
– مهندسی مدل
در این مرحله، از تمام اطلاعات مرحله برنامه ریزی برای ساخت و آموزش یک مدل یادگیری ماشین استفاده میکنین. مثلا، ردیابی معیارهای مدل، اطمینان از مقیاس پذیری و استحکام و بهینه سازی منابع ذخیره سازی و پردازشی.
- با انجام تحقیقات گسترده، معماری موثری رو برای مدل ایجاد کنین
- معیارهای مدل رو تعریف کنین
- آموزش و اعتبارسنجی مدل رو با استفاده از مجموعه داده آموزش و اعتیارسنجی انجام بدین
- آزمایش ها، کلان داده ها، ویژگی ها، تغییرات کد و پایپ لاین یادگیری ماشین رو ردیابی کنین
- فشرده سازی و ترکیب بندی مدل رو انجام بدین
- نتایج رو با مشارکت متخصصان حوزه تفسیر کنین
در این مرحله بر روی معماری مدل، کیفیت کد، آزمایش های یادگیری ماشین، آموزش مدل و مجموعه سازی تمرکز میشه.
ویژگی ها، فراپارامترها، آزمایش های یادگیری ماشین، معماری مدل، محیط توسعه و کلان داده ها برای تکرارپذیری و ثبات بیشتر ذخیره و نسخه سازی میشن.
– ارزیابی مدل
حالا که نسخه مدل رو نهایی کردین، وقتش رسیده تا معیارهای مختلف رو آزمایش کنین. با این کار مطمئن میشین که مدل آماده تولید و بهره برداری هستش.
اول باید مدل خودتون رو با استفاده از یک مجموعه داده آزمایشی تست کنین تا مطمئن بشین متخصصان حوزه میتونن خطا در پیش بینی ها رو شناسایی کنن. همچنین باید مطمئن بشین که از چارچوب های صنعتی، اخلاقی و قانونی برای ساخت راه حل های هوش مصنوعی پیروی کردین.
علاوه بر این، مدل خودتون رو بر روی داده های تصادفی و واقعی آزمایش کنین تا میزان استحکام اون رو بسنجین. مطمئن بشین که مدل اندازه کافی سریع استنتاج میکنه تا مقدار مورد نظر رو به دست بیاره.
در نهایت، نتایج رو با معیارهای موفقیت برنامه ریزی شده مقایسه کنین و تصمیم بگیرین که آیا مدل قابلیت اجرا شدن داره یا نه. در این مرحله، هر فرآیند برای حفظ کیفیت و تکرارپذیری ثبت و نسخه سازی میشه.
– پیاده سازی مدل
در این مرحله، مدل های یادگیری ماشین رو باید در سیستم فعلی پیاده سازی کنین. مثلا معرفی مدل برچسب گذاری خودکار انبار با استفاده از شکل محصول. به این منظور یک مدل دید کامپیوتری در سیستم فعلی مستقر میشه که برای چاپ برچسب ها از تصاویر دوربین استفاده میکنه.
به طور کلی، مدل ها رو میشه روی سرور ابری و محلی، مرورگر وب، پکیج به عنوان نرم افزار و دستگاه Edge پیاده سازی کرد. بعد از اون، میتونین از API، برنامه تحت وب، افزونه ها یا داشبورد برای دسترسی به پیش بینی ها استفاده کنین.
در فرآیند پیاده سازی، سخت افزار استنتاج رو تعریف میکنین. باید مطمئن بشین که حافظه رم، حافظه ذخیره سازی و توان پردازشی کافی برای تولید نتایج با سرعت بالا وجود داشته باشه. پس از این، با استفاده از تست A/B عملکرد مدل رو در شرایط بهره برداری ارزیابی میکنیم و از قابل پذیرش بودن نتایج توسط کاربر مطمئن میشیم.
استراتژی پیاده سازی یک مدل یادگیری ماشین هم اهمیت زیادی داره. باید مطمئن بشین که تغییرات یکپارچه هستن و تجربه کاربری رو بهبود دادن. علاوه بر این، یک مدیر پروژه باید یک برنامه مدیریت حوادث رو تهیه کنه. این برنامه باید یک استراتژی بازگشتی، نظارت مداوم، تشخیص ناهنجاری و به حداقل رساندن تلفات رو شامل بشه.
– نظارت و نگهداری
پس از استقرار مدل برای تولید، به نظارت و بهبود مداوم سیستم نیاز دارین. شما باید معیارهای مدل، عملکرد سخت افزار و نرم افزار و همینطور رضایت مشتری رو زیرنظر داشته باشین. این نظارت کاملا خودکار انجام میشه و متخصصان در مورد ناهنجاری ها، کاهش عملکرد مدل و سیستم و نظرات بد مشتریان مطلع میشن.
بعد از دریافت هشدار کاهش عملکرد، مسائل باید ارزیابی بشن و سعی کنین تا مدل رو بر روی مجموعه داده های جدید آموزش بدین یا تغییراتی رو در معماری مدل ایجاد کنین. این اقدامات بخشی از یک فرآیند مستمر در نظر گرفته میشن.
در موارد نادر، برای بهبود پردازش داده ها، تکنیک های آموزش مدلسازی، به روزرسانی نرم افزار و سخت افزار جدید و معرفی یک چارچوب جدید برای یکپارچه سازی مداوم، ممکنه مجبور بشین چرخه عمر مدل یادگیری ماشین رو به طور کامل اصلاح کنین.
آشنایی با مزایا یادگیری ماشین
ماشین لرنینگ مزایا و چالشهای مختلفی دارد که در این بخش به چند مورد از مهمترین آنها میپردازیم.
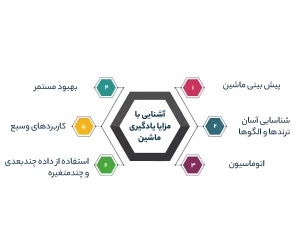
1. پیش بینی ماشین
طبیعتا ماشینها در آنالیز مجموعههای وسیعی از داده با متغیرهای پیچیده بهتر و سریع تر از انسان عمل میکنن. در واقع محققین معتقدن تکنیکهای مدلسازی پیش بینی کننده حتی میتونن بهتر از پزشکان بیماری ها و روش درمانی رو تشخیص بدن. حتی در بعضی از بررسیها این برتری میتونه تا 40 درصد باشه.
2. شناسایی آسان ترندها و الگوها
یادگیری ماشین میتونه حجم وسیعی از داده رو خیلی سریع بررسی و ترندها و الگوهای مشخص رو شناسایی کنه که به سادگی توسط انسان قابل تشخیص نیستن.
3. اتوماسیون
با استفاده از یادگیری ماشین دیگه نیازی نیست تک تک گام های پروژه خودتون رو زیر نظر بگیرین. از اونجایی ماشین لرنینگ یعنی توانمند کردن ماشین ها برای یادگیری، امکان انجام پیش بینی ها و بهبود خودکار الگوریتم ها وجود داره.
4. بهبود مستمر
الگوریتم های یادگیری ماشین تجربه به دست میارن و هم کارایی و هم دقت اونها به مرور بهبود پیدا میکنه. اینطوری میتونن تصمیمات بهتری بگیرن.
5. استفاده از داده چندبعدی و چندمتغیره
الگوریتم های یادگیری ماشین در استفاده از دادههای چندبعدی و چندمتغیره عملکرد خیلی خوبی دارن و میتونن این عملکرد رو در محیط های پویا و با عدم قطعیت هم نشون بدن.
6. کاربردهای وسیع
شما میتونین در صنایع مختلف از یادگیری ماشین بهره ببرین. برای مثال استفاده از ماشین لرنینگ در خرده فروشیهای آنلاین، نرم افزارهای مدیریت ارتباط با مشتری یا صنعت مراقبتهای بهداشتی میتونه به شخصی سازی تجربه کاربرها کمک کنه.
چالش ها و معایب یادگیری ماشین
1- تهیه داده
همون طور که گفتیم، یادگیری ماشین به مجموعههای وسیعی از داده نیاز داره تا با استفاده از اونها آموزش ببینه. این داده ها باید فراگیر، بی طرفانه و با کیفیت باشن. علاوه بر این، برای تولید دادههای جدید مطابق با کیفیت مورد نظر باید مدت زمانی رو انتظار کشید.
2- زمان و منابع
ماشین لرنینگ برای یادگیری الگوریتمها و توسعه یافتن به سطحی که بتونن با دقت و تناسب قابل قبولی به اهداف مورد نظر دست پیدا کنن، به زمان کافی نیاز دارن. علاوه بر این، عملیاتی کردن یادگیری ماشین به منابع وسیعی نیاز داره که مهمترین اونها میتونه قدرت پردازشی بالا در کامپیوترهای مورد استفاده باشه.
3- تفسیر نتایج
یکی دیگه از چالش های یادگیری ماشین، توانایی تفسیر دقیق نتایج تولید شده توسط الگوریتم هستش. شما باید با دقت کامل الگوریتم ها رو با توجه به اهدافتون انتخاب کنین.
4- حساسیت بالا به خطا
اگرچه یادگیری ماشین عملکردی خودکار داره اما خیلی نسبت به خطاها حساسه. فرض کنین الگوریتم رو با استفاده از یک مجموعه داده کوچک و غیرفراگیر آموزش دادین. پیش بینی های خروجی از یک مجموعه آموزشی مغرضانه طبیعتا مغرضانه خواهد بود. در چنین شرایطی، تبلیغات نامرتبط به مشتریان نمایش داده میشه.
وقتی با ماشین لرنینگ سر و کار دارین، ممکنه این اشتباهات مجموعهای از خطاها رو ایجاد کنه که برای مدت زمان طولانی تشخیص داده نشه. وقتی هم که این خطاها شناسایی میشن، تشخیص منبع ایجاد مشکل زمان بر هستش و تصحیح اون به زمان حتی بیشتری نیاز داره.
داده کاوی، یادگیری ماشین و یادگیری عمیق چه تفاوتی با هم دارند؟
از نظر مفهومی، یادگیری عمیق یا Deep Learning در واقع یکی از زیرمجموعههای یادگیری ماشین یا Machine Learning به حساب میاد. حتی میشه اینطور فرض کرد که یادگیری عمیق همون یادگیری ماشینه و عملکردی مشابه داره. شاید همین موضوع باعث شده تا گاهی اوقات این دو مفهوم به جای هم به کار برن. اما در واقعیت ML و DL از نظر توانمندی ها با همدیگه تفاوت دارن.
اگرچه مدلهای ساده یادگیری ماشین به مرور زمان و با ورود مجموعه داده های جدید، عملکرد خودشون رو برای رسیدن به هدف مشخص شده بهبود میدن اما هنوز هم به نوعی نیازمند نظارت انسانی هستن. اگر یک الگوریتم هوش مصنوعی پیش بینی اشتباهی رو ارائه بده، یک مهندس نرم افزاری باید وارد عمل بشه و تنظیمات لازم رو انجام بده.
اما در یک مدل یادگیری عمیق، الگوریتم میتونه تشخیص بده آیا پیش بینی انجام شده به اندازه کافی دقیق هست یا نه. این کار به صورت خودکار و با استفاده از شبکه عصبی طراحی شده برای الگوریتم انجام میشه و هیچ نیازی به کمک انسان وجود نداره.
مثلا فرض کنید یک الگوریتم برای روشن شدن خودکار چراغ قوه یا یک چراغ طراحی شده. با استفاده از یادگیری ماشین میشه الگوریتم رو طوری برنامه نویسی کرد که وقتی کلمه «تاریکی» رو شنید به صورت خودکار وظیفه مذکور یعنی روشن کردن چراغ قوه یا چراغ رو انجام بده. با گذشت زمان ممکنه الگوریتم بتونه یاد بگیره وقتی جملهای حاوی این کلمه باشه باز هم چراغ رو روشن کنه.
اما اگر برای این مدل از الگوریتم یادگیری عمیق استفاده کنیم، الگوریتم میتونه عباراتی مثل «نمیتونم ببینم» یا «کلید چراغ کار نمی کنه» رو هم متوجه بشه و چراغ رو به صورت خودکار روشن کنه.
در واقع یک مدل یادگیری عمیق با استفاده از یک روش پردازشی منحصر به فرد توانایی یادگیری داره. این روش به نوعی اجازه میده الگوریتم یک مغز اختصاصی داشته باشه.
بنابراین میتونیم تفاوتهای بین این دو تکنولوژی رو به صورت زیر توضیح بدیم:
- ماشین لرنینگ با استفاده از الگوریتم ها، داده رو تجزیه و تحلیل می کنه و از اون یاد می گیره. سپس با توجه به نکاتی که یاد گرفته، در حوزه ای که مشخص شده تصمیم آگاهانه ای می گیره.
- در یادگیری عمیق، الگوریتم ها ساختاری چند لایه دارن تا یک شبکه عصبی مصنوعی رو تشکیل بدن. این شبکه اجازه میده تا الگوریتم به صورت مستقل نکات رو بیاموزه و هوشمندانه تصمیم بگیره.
- یادگیری عمیق یکی از زیرمجموعه های یادگیری ماشین به حساب میاد. اگرچه هر دو مفهوم در یک حوزه وسیع تر به نام هوش مصنوعی قرار می گیرن، اما یادگیری عمیق بیشترین شباهت رو به نحوه فکر کردن انسان داره.
اما داده کاوی (Data Mining) فرآیندی هستش که در اون تلاش میشه الگوها و قوانین پنهان در یک مجموعه داده موجود شناسایی بشن. در واقع داده کاوی از اصول ساده ای مثل اشتراک، همبستگی برای تصمیم گیری و موارد دیگه استفاده میکنه.
برای پیاده سازی تکنیکهای داده کاوی باید دو بخش فراهم باشه؛ بخش اول دیتابیس و بخش دوم یادگیری ماشین هستش. دیتابیس تکنیکهای مدیریت داده و ماشین لرنینگ تکنیک های آنالیز داده رو شامل میشه. اما برای پیاده سازی تکنیک های یادگیری ماشین صرفا باید الگوریتمهای مناسب رو توسعه داده.
در داده کاوی مفهومی تحت عنوان خودیادگیری وجود نداره و همه چیز بر اساس قوانین و اصول از پیش تعیین شده هستش. داده کاوی در نهایت میتونه برای یک مشکل کاملا مشخص و موجود راهکاری رو ارائه بده. اما الگوریتمهای یادگیری ماشین میتونن قوانین رو با توجه به شرایط و مجموعه دادههای دریافتی تغییر بدن.
در داده کاوی از دیتابیس، سرور ذخیره سازی داده، موتور داده کاوی یا تکنیک های ارزیابی الگو استفاده میشه تا اطلاعات مفید استخراج بشه. در حالی که در یادگیری ماشین با استفاده از شبکه های عصبی، مدل پیش بینی کننده و الگوریتمهای خودکار، تصمیمات هوشمندانه اتخاذ میشه.
به طور کلی میشه گفت ماشین لرنینگ نسبت به داده کاوی، دقیق تره و ضریب خطای پایین تر داره. علاوه بر این، الگوریتمهای یادگیری ماشین این توانایی رو دارن تا به صورت مستقل تصمیم بگیرن و مشکل رو حل کنن.
سوالات متداول
یادگیری ماشین چیه؟
ماشین لرنینگ یا Machine Learning یکی از زیرشاخههای هوش مصنوعیه که با کمک الگوریتم های هوشمندش میتونه اطلاعات رو پیش بینی کنه و در کمترین زمان تصمیمات هوشمندانه و حیاتی بگیره.
الگوریتم های ماشین لرنینگ چند نوع هستن؟
الگوریتم های یادگیری ماشین با توجه به میزان نظارت و دخالت انسان به چهار دسته تحت نظارت، بدون نظارت، نیمه نظارتی و تقویت کننده دسته بندی میشن. هر کدوم از این الگوریتم ها برای مقاصد مشخص عملکرد بهتری رو ارائه میدن.
یادگیری ماشین چه کاربردهایی داره؟
با توجه به سرعت و دقت به مراتب بالاتر الگوریتم های هوش مصنوعی در تحلیل کلان داده ها، تکنولوژی ماشین لرنینگ میتونه در صنایع مختلفی مورد استفاده قرار بگیره. صنعت بهداشت و درمان، فروشگاه ها و سرویس های اینترنتی، مدیریت ارتباط با مشتری و بسیاری دیگر کاربردهای این تکنولوژی رو تشکیل میدن.
ماشین لرنینگ چه مزایایی داره؟
به طور کلی یادگیری ماشین مزایایی مثل اتوماسیون، شناسایی سریع و دقیق الگوها و ترندها در حجم های وسیعی از داده، کاربردهای متنوع، یادگیری خودکار و بهبود مستمر رو ارائه میده.